Stockage Ceph

Ceph est un peu le couteau suisse du stockage distribué. Il est open source, multi-modes (bloc, fichier et object) sans SPOF et massivement scalable (exaoctet). Dans cet article, je vais aborder le déploiement d’un cluster CEPH avec l’outil DeepSea…
L’objectif de l’article n’est pas de détailler le fonctionnement de CEPH, pour cela je vous conseille plutôt la présentation de Sage Weil.
Néanmoins, voici un petit rappel des principaux composants d’un cluster CEPH:
- Object Storage Daemon (OSD): gére les disques durs et la réplication des données
- Monitor (MON): maintient les différentes maps nécéssaires au fonctionnement du cluster et gére l’authentification.
- Manager (MGR): collecte les métriques du cluster et fourni différents modules pour la supervision et le monitoring (Dashboard, Prometheus, Zabbix, API RESTful..)
- Metadata Server (MDS): nécessaire pour utiliser cephFS
- Rados Gateway (RGW): fournit l’interface pour le stockage Objet (S3 ou Swift)
DeepSea est une solution open source de déploiement automatisé de CEPH proposée par SUSE dans son offre SUSE Entreprise Storage (SES 6). Elle est basée sur l’outil de gestion de configuration SaltStack.
Pré-requis
Pour cette démo, j’ai déployé 4 VMs sous openSUSE LEAP 15.1 dans un lab VMware:
- ceph-0.exemple.com : VM d’administration
- 1 CPU, 2 GB de RAM
- ceph-[1.3].exemple.com : noeuds de stockage du cluster CEPH
- 2 CPU, 4GB de RAM,
- 2 disques de 50GB pour les OSD
- 1 disques de 25GB pour les journaux et RocksDB bluetore
installation CEPH en version Nautilus
Sur tous les VMs: ceph-[0.3].exemple.com
désactiver apparmor et le firewall
1$ sudo systemctl stop firewalld && systemctl disable firewalld
2$ sudo systemctl stop apparmor && systemctl disable apparmor
ajouter le dépôt pour CEPH
1$ sudo zypper addrepo https://download.opensuse.org/repositories/filesystems:ceph:nautilus/openSUSE_Leap_15.1/filesystems:ceph:nautilus.repo
2
3$ sudo zypper lr
4Repository priorities are without effect. All enabled repositories share the same priority.
5
6# | Alias | Name | Enabled | GPG Check | Refresh
7---+---------------------------+------------------------------------+---------+-----------+--------
81 | filesystems_ceph_nautilus | Ceph Nautilus (openSUSE_Leap_15.1) | Yes | (r ) Yes | No
92 | openSUSE-Leap-15.1-1 | openSUSE-Leap-15.1-1 | Yes | (r ) Yes | Yes
ajouter l’agent SALT (minion) et configurer l’adresse du master
1$ sudo zypper in salt-minion
2$ sudo echo "master: ceph-0.exemple.com" > /etc/salt/minion.d/master.conf
3$ sudo systemctl start salt-minion.service && systemctl enable salt-minion.service
Sur la VM d’admin: ceph-0.exemple.com
Installer le master SALT et valider les clés des minions
1$ sudo zypper in salt-master
2$ sudo systemctl enable salt-master.service && systemctl start salt-master.service
3
4$ sudo salt-key --accept-all
5The following keys are going to be accepted:
6Unaccepted Keys:
7ceph-O.exemple.com
8ceph-1.exemple.com
9ceph-2.exemple.com
10ceph-3.exemple.com
11Proceed? [n/Y]
12Key for minion ceph-0.exemple.com accepted.
13Key for minion ceph-1.exemple.com accepted.
14Key for minion ceph-2.exemple.com accepted.
15
16$ sudo salt-key --list-all
17Accepted Keys:
18ceph-0.exemple.com
19ceph-1.exemple.com
20ceph-2.exemple.com
21ceph-3.exemple.com
22Denied Keys:
23Unaccepted Keys:
24Rejected Keys:
Installer DeepSea et ajouter le grain deepsea sur tous les noeuds du cluster
1$ sudo zypper in deepsea
2$ sudo salt -E 'ceph-[0-3]'.exemple.com grains.append deepsea default
3ceph-0.exemple.com:
4 ----------
5 deepsea:
6 - default
7ceph-2.exemple.com:
8 ----------
9 deepsea:
10 - default
11ceph-1.exemple.com:
12 ----------
13 deepsea:
14 - default
15ceph-3.exemple.com:
16 ----------
17 deepsea:
Tester la communication entre le master et les minions qui portent le grain deepsea
1$ sudo salt -G 'deepsea:*' test.ping
2ceph-3.exemple.com:
3 True
4ceph-1.exemple.com:
5 True
6ceph-2.exemple.com:
7 True
8ceph-0.exemple.com:
9 True
Modifier la configuration globale de DeepSea
1$ sudo cat << EOF > /srv/pillar/ceph/stack/global.yml
2DEV_ENV: True
3subvolume_init: disabled
4EOF
DEV_ENV: True: permet de déployer des cluster < à 4 noeudssubvolume_init: disabled: permet d’éviter les Pb de snapshot BTRFS si /var/lib/ceph fait partie du subvolume racine (référence)
Appliquer la modification
1$ sudo salt '*' saltutil.sync_all
2$ sudo salt -G 'deepsea:*' state.apply ceph.subvolume
L’installation de CEPH peut commencer. Elle se déroule en 4 phases
Lancer la phase de préparation
1$ sudo deepsea salt-run state.orch ceph.stage.prep
2
3Starting orchestration: ceph.stage.prep
4Parsing orchestration ceph.stage.prep steps... ⏳
5
6[parsing] on master
7 |_ ceph.stage.prep
8
9[parsing] on ceph-0.exemple.com
10 |_ ceph.sync
11 ceph.metapackage
12 ceph.repo
13 ceph.salt.crc.master
14 ceph.salt-api
15 ceph.updates
16------8<------
17
18// si tout ce passe bien vous devez obtenir à la fin
19Ended stage: ceph.stage.prep succeeded=17/17 time=241.2s
utiliser la commande deepsea pour lancer les différentes phases permet d’obtenir un affichage plus verbeux. Il est également possible de lancer la commande
deepsea monitordans un autre terminal pour suivre les opérations
Lancer la phase de découverte du cluster
1$ sudo deepsea salt-run state.orch ceph.stage.discovery
2
3// si tout ce passe bien vous devez obtenir à la fin
4Ended stage: ceph.stage.discovery succeeded=3/3 time=12.5s
Il faut maintenant indiquer à DeepSea le rôle CEPH affecté à chaque noeud. Pour cette prise en main, les noeuds de stockages supportent les rôles OSD, MON et MGR (voir doc)
1$ sudo cat /srv/pillar/ceph/proposals/policy.cfg
2
3## Cluster Assignment
4cluster-ceph/cluster/*.sls
5
6## Roles
7# ADMIN
8role-master/cluster/ceph-0.exemple.com.sls
9role-admin/cluster/ceph-0.exemple.com.sls
10
11# Monitoring
12role-prometheus/cluster/ceph-0.exemple.com.sls
13role-grafana/cluster/ceph-0.exemple.com.sls
14
15# MON
16role-mon/cluster/ceph-[1-3].exemple.com.sls
17
18# MGR (mgrs are usually colocated with mons)
19role-mgr/cluster/ceph-[1-3].exemple.com.sls
20
21# COMMON
22config/stack/default/global.yml
23config/stack/default/ceph/cluster.yml
24
25# Storage
26role-storage/cluster/ceph-[1-3].exemple.com.sls
Lancer l’étape de configuration
1$ sudo deepsea salt-run state.orch ceph.stage.configure
2
3// si tout ce passe bien vous devez obtenir à la fin
4Ended stage: ceph.stage.configure succeeded=17/17 time=120.0s
Dernière étape, il faut indiquer à DeepSea comment utiliser les disques. Pour cela, vous pouvez lister les disques sur les serveurs
1$ sudo salt-run disks.details
2ceph-1.exemple.com:
3 |_
4 ----------
5 /dev/sdb:
6 ----------
7 model:
8 Virtual disk
9 rotational:
10 1
11 size:
12 50.00 GB
13 vendor:
14 VMware
15 |_
16 ----------
17 /dev/sdc:
18 ----------
19 model:
20 Virtual disk
21 rotational:
22 1
23 size:
24 50.00 GB
25 vendor:
26 VMware
27 |_
28 ----------
29 /dev/sdd:
30 ----------
31 model:
32 Virtual disk
33 rotational:
34 1
35 size:
36 25.00 GB
37 vendor:
38 VMware
Sur chaque noeud, on dispose de 2 disques de 50GB pour le stockage et 1 disque de 25GB pour simuler un SSD dédié aux journaux et RocksDB Bluestore.
Le fichier /srv/salt/ceph/configuration/files/drive_groups.yml permet de définir l’utilisation des disques (voir doc).
1$ sudo cat /srv/salt/ceph/configuration/files/drive_groups.yml
2
3drive_group_default_name:
4 target: '*'
5 data_devices:
6 size: '50GB'
7 db_devices:
8 size: '25GB'
9 osds_per_device: 1
10 db_slots: 2
11 format: bluestore
12 encrypted: False
Ici, tous les disques de 50GB sont dédiés aux OSD et le disque de 25GB est dédié aux journaux bluestore (pour les 2 OSD).
Pour appliquer la configuration, lancez la phase de déploiement
1$ sudo deepsea salt-run state.orch ceph.stage.deploy
2
3// si tout ce passe bien vous devez obtenir à la fin
4Ended stage: ceph.stage.deploy succeeded=60/60 time=567.6s
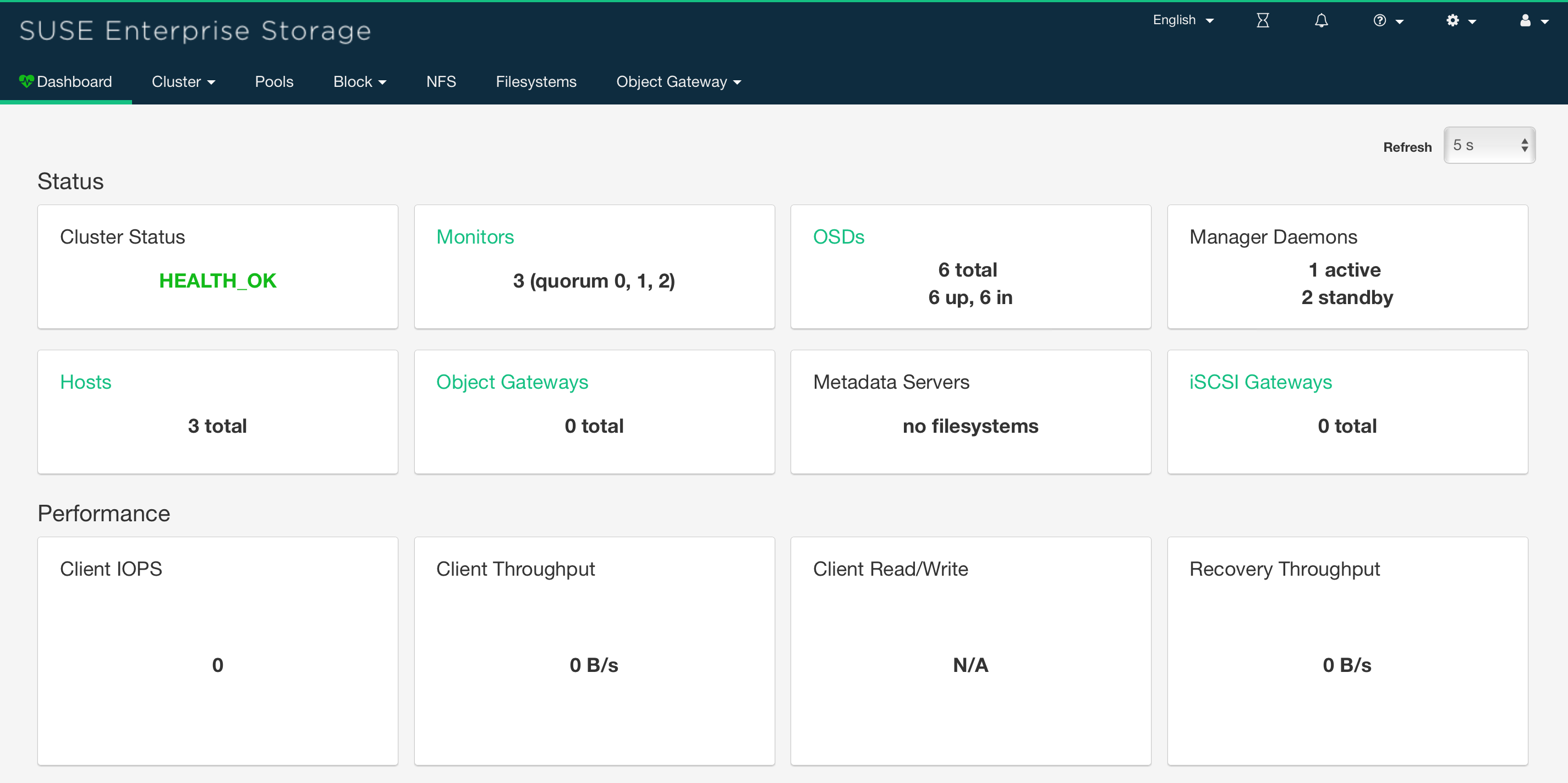
A ce stage, le cluster CEPH est opérationnel
1$ sudo ceph -s
2 cluster:
3 id: 875feeab-694a-488d-91ea-243197f59ffd
4 health: HEALTH_OK
5
6 services:
7 mon: 3 daemons, quorum ceph-1,ceph-2,ceph-3 (age 5m)
8 mgr: ceph-2(active, since 68s), standbys: ceph-1, ceph-3
9 osd: 6 osds: 6 up (since 3m), 6 in (since 3m)
10
11 data:
12 pools: 0 pools, 0 pgs
13 objects: 0 objects, 0 B
14 usage: 81 GiB used, 294 GiB / 375 GiB avail
15 pgs:
Les 6 OSDs (3 noeuds de 2 disques) sont “up” ainsi que les 3 monitors en cluster
Il reste à obtenir l’accès au dashboard
1$ sudo ceph mgr services | grep dashboard
2 "dashboard": "https://ceph-2.exemple.com:8443/",
3
4
5$ sudo salt-call grains.get dashboard_creds
6local:
7 ----------
8 admin:
9 2ocgtdH3o6C
La suite au prochain épisode…