Proxmox HCI

Ce billet propose une approche pragmatique du dimensionnement d’un cluster Proxmox pour faire de l’hyperconvergence.
Photo by Marc PEZIN on Unsplash
Dans le domaine de la virtualisation, l’hyperconvergence ou HCI (Hyper-Converged Infrastructure) permet de combiner les ressources de calculs, de stockages et de réseaux au sein d’une même solution logicielle. Contrairement aux solutions dites “convergées” comme VMware vSphere, le HCI vous dispense d’une solution de stockage de type SAN (FC, iSCSI) ou NAS (NFS) souvent très onéreuses (sans parler des problèmes bien connus de vendor lock-in).
Dans le monde propriétaire, les cadors du marché comme Dell/EMC (VXrail), VMware (vSAN) ou encore Nutanix (AOS) se taillent la part du lion. Il existe pourtant une alternative libre tout à fait crédible avec Proxmox VE (Virtual Environment) et Ceph.
Proxmox VE
Proxmox VE est une solution bien connue de virtualisation basée sur Debian. Elle permet de créer facilement des clusters pour lancer des machines virtuelles KVM ou des conteneurs LXC.
Proxmox VE peut piloter du stockage Ceph depuis la même interface web et proposer ainsi une solution HCI complète avec de nombreux avantages:
- migration à chaud des VMs (pratique pour faire des maintenances sur les noeuds)
- haute disponibilité (relance des VMs en cas de crash d’un hôte sur les noeuds resrtants)
- architecture de type scale-out (il suffit d’ajouter des noeuds pour augmenter les capacités de traitements et de stockages)
Proxmox propose également une sauvegarde des VMs parfaitement intégrée: Proxmox Backup Server
Ceph
Ceph est une solution SDS (Software-Defined Storage) libre de stockage distribuée qui propose nativement des accès en mode bloc (RBD: Rados Block Device), en mode fichier (CephFS: Ceph File System) et objet compatible S3 (RGW: Rados Gateway).
Dans Ceph, chaque disque est piloté individuellement par un daemon appelé OSD (Objet Storage Daemon). Ainsi, un noeud avec 12 disques fera tourner 12 daemons OSD). Pour gérer le fonctionnement du cluster, Ceph utilise deux autres daemons appelés MON (monitor) et MGR (manager).
Le détail du fonctionnement de Ceph dépasse un peu le cadre de ce billet, je vous renvoie à l’excellente présentation du fondateur si vous souhaitez approfondir cette partie:
Dimensionnement
Même si l’intégration de CEPH dans Proxmox permet de masquer un peu sa complexité, il est important de bien comprendre certains concepts pour éviter les erreurs de designs.
Pour chaque conteneur LXC ou machine virtuelle KVM, Proxmox va créer dans Ceph un périphérique de bloc appelé RBD (Rados Block Device). Sur l’hôte Proxmox qui exécute la VM ou le conteneur, le module Kernel RBD va “découper” ce disque en objets et les répartir sur différents OSD (les disques) en utilisant un algorithme déterministe nommé CRUSH (Controlled Replication Under Scalable Hashing). La protection des données est assurée par une réplication à 3 des objets dans le cluster (CEPH supporte également du code à effacement mais il n’est pas recommandé et proposé par Proxmox).
Cette description est volontairement un peu sommaire, dans les faits, le client Ceph va déterminer un PG (Placement Group) lui-même associé à un OSD. Le daemon monitor de Ceph se charge de maintenir la carte de correspondance entre le PG et l’OSD (Sage Weil l’explique plus en détail dans la vidéo proposée). Je vais revenir un peu cette histoire de réplication pour bien comprendre les enjeux.
Quand le module RBD cherche à écrire un objet, il va déterminer un OSD primaire et ouvrir une connexion TCP vers l’adresse IP du noeud qui contient l’OSD en question et le port TCP qu’il utile. Ensuite, l’OSD primaire va déterminer les OSD secondaires pour faire les 2 autres copies (réplication à 3) et ouvrir à son tour des connexions vers ces noeuds. Le module RBD obtient l’acquittement de l’écriture seulement lorsque les 2 OSDs secondaires ont confirmé les écritures à l’OSD primaire.
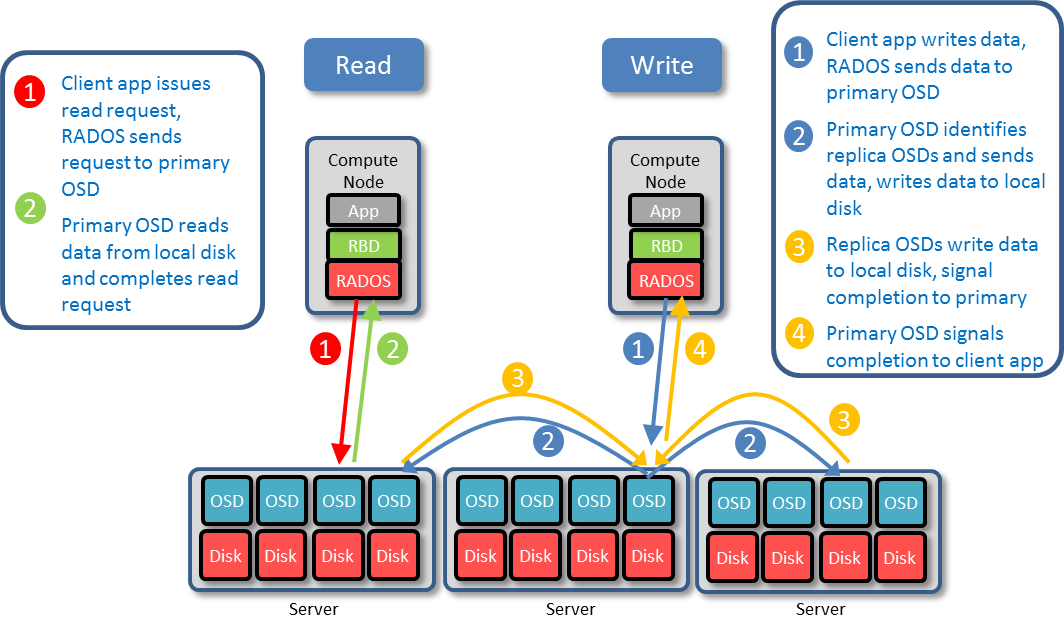
Pourquoi je vous détaille ce fonctionnement ? Tout simplement pour introduire un élément fondamental d’une architecture CEPH: Il faut une infra réseau performante (10GbE minimum recommandé), résiliente (prévoir des agrégats) et à faible latence.
L’autre conséquence de la réplication à 3, c’est la très faible efficacité du stockage avec ratio utile / brut d’environ 33%. A titre de comparaison un volume en RAID-6 propose une efficacité de 66,6%. En clair, un cluster de 3 noeuds avec chacun 5 disques de 1TB proposera moins de 5TB de stockage utile pour les VMs.
Ce chiffre de 3 noeuds n’est pas choisi par hasard puisqu’il s’agit d’un minimum pour déployer un cluster HCI Proxmox en production:
- un nombre impair facilite l’obtention d’un quorum
- dans Proxmox, le
failure domainde Ceph est défini au niveau noeud. Pour obtenir un FTT (Failure To Tolerate) d’un noeud, il faut en faut au minimum 3 (min_size = 2) - ceph recommande au moins 3 monitors dans un cluster (daemon qui maintient la cohérence du cluster)
Il s’agit bien ici d’un minimum, Ceph étant un stockage de type scale-out, les performances augmentent avec le nombre de noeuds et d’OSDs (disques).
Cas d’étude
Pour illustrer un peu la démarche et les differentes ressources nécessaires, je vous propose un cas d’étude classique pour un petit cluster:
- nombre de noeuds: 3
- nombre de VMs: 100
- volumétrie utile cible: (40GB par VM) x 100 VMs = 4TB
- 2 vCPU et 2 GB de vRAM par machine virtuelle
- usages: WEB, DB, SMTP, DNS, LDAP…
- possibilité de perdre 1 noeud
Le stockage
Vous l’avez compris, le dimensionnement des noeuds du cluster Proxmox découle directement de la volumétrie de stockage dont vous souhaitez disposer (et accessoirement un peu de votre budget).
Là encore, il faut plonger dans les entrailles de Ceph pour bien comprendre les différentes alternatives. Pour accéder au disque, l’OSD ne va pas utiliser un système de fichiers standard (EXT4, XFS, ZFS…) mais un procédé nommé BlueStore qui consiste à attaquer directement un periphérique de bloc brut (raw device). L’équivalent de la table d’inodes va être géré avec une base de données de type clé-valeur RockDB.
Concrètement, chaque disque dur va être découpé avec LVM en 2 volumes logiques. Un premier volume de faible dimension formaté en XFS va contenir la RockDB et un journal d’écriture de type WAL (Write-Ahead Log). Le reste du disque est utilisé directement sans formatage pour stocker les objets.
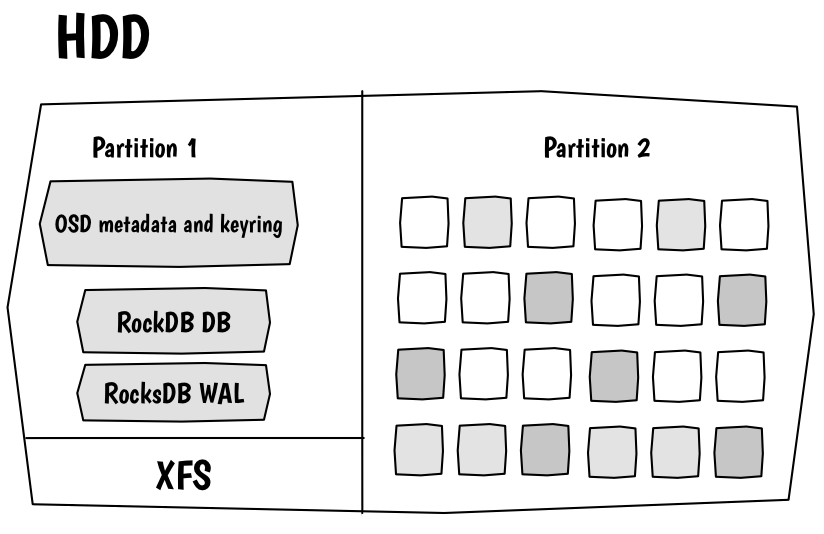
BlueStore est très efficace avec des SSD mais il peut être pénalisé par les temps d’accès plus long et les faibles capacités en IOPS des disques mécaniques. Heureusement, il existe une solution pour améliorer les performances qui consiste à délocaliser la rockdb et le journal sur des disques SSD plus rapides.
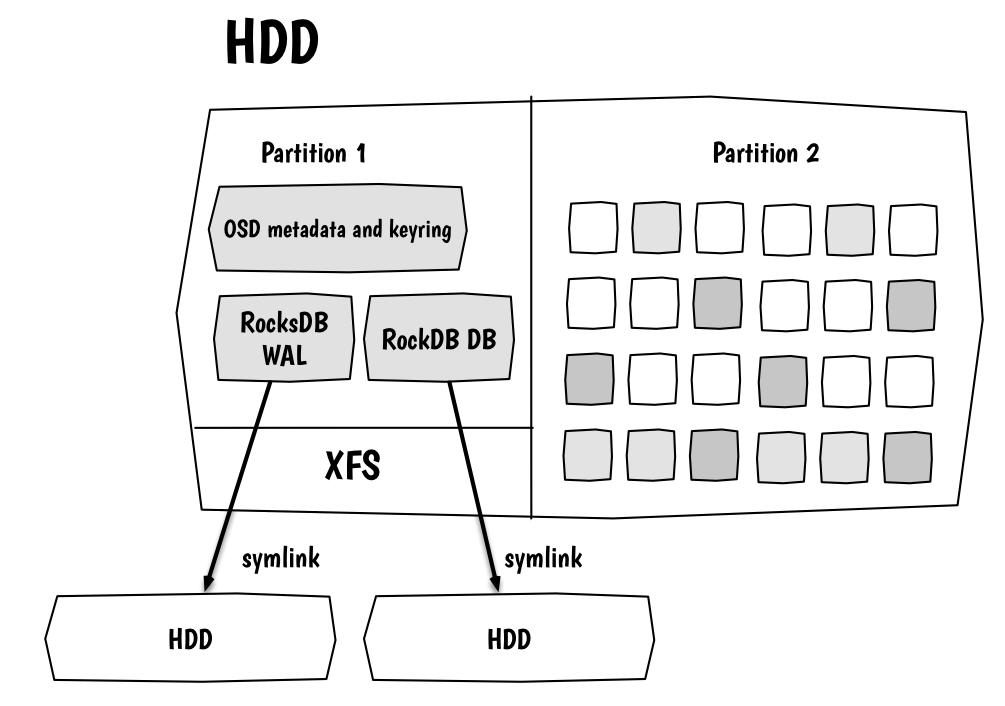
La documentation Suse SES 7 recommande jusqu’à 6 OSD géré par un SSD et 12 OSD pour un disque NVMe. Là, il faut bien comprendre qu’en cas de défaillance du SSD, il faut reconstruire les données de tous les OSD qu’il gère. Ce n’est pas un problème en soit puisque Ceph est très robuste et il est possible de reconstruire facilement les disques perdus à partir des réplicats (merci le réseau 10GbE) mais l’impact sur les performances risque de rendre votre cluster beaucoup moins réactif. Il faut donc faire preuve de prudence si vous avez un faible nombre d’OSDs et de noeuds.
Le dimensionnement standard de ces SSD consiste à réserver au moins 2% (jusqu’à 4% pour faire du stockage S3) de la taille du disque mécanique par OSD à gérer.
Exemple: mon noeud contient 4 disques mécaniques de 2TB. Je vais provisionner un SSD de:
- Nb disques OSD x taille disque x 0,02
- 4 x 2TB x 0,02 = 0,16TB (~160GB)
Parmi les autres points à surveiller au niveau matériel, il faut s’assurer que Ceph peut accéder directement à chaque disque en mode JBOD au niveau du contrôleur disques. Dans le cas contraire, il est parfois possible de faire des configurations RAID-0 individuelles.
Il est temps de mettre en pratique toutes ces informations avec notre cas d’étude.
Voici les questions auxquelles il va falloir répondre:
- quel nombre de disques: en fonction du nombre d’emplacements disponibles sur le serveur
- quelle technologie de disques: HDD, SSD en fonction du budget et des performances attendues (IOPS)
- quelle capacité individuelle: en fonction de la volumétrie à atteindre (rappel : 4TB)
A partir de là, il n’y a pas de recette miracle pour résoudre cette équation et je pars du principe qu’il faut privilégier du stockage SSD. Je consulte un peu les tarifs et trouve un bon compromis prix / volumétrie avec des SSD de 1TB NVMe (par exemple: Samsung 980 PRO NVMe M.2 PCIe 4.0 1TB). Ca tombe bien, 1TB c’est également la taille minimale recommandée dans la documentation Ceph. Autre argument en faveur de ce choix, ce disque est de catégorie MLC avec une endurance adaptée pour ce type d’usage (on ne va pas miner du Chia hein !)
J’entre 1TB par disque et une volumétrie cible de 4TB dans le calculateur Ceph et je fais varier le nombre de disque pour atteindre 4TB à 85% de taux d’utilisation brut du cluster (à 95% il passe en lecture seule). Sur 3 noeuds, j’obtiens un total de 5 disques par noeud pour tout juste 4TB. Par sécurité, il faudrait donc plutôt prévoir 6 disques de 1TB par noeud.
Avec une volumétrie plus conséquente, il faudrait envisager des disques mécaniques. Dans ce cas, il faudrait prévoir si possibles des disques SAS 10K tr/mn et les disques SSD pour BlueStore.
Voici une petite simulation pour le cas d’étude sur la base de disques de 1,2TB: avec le calculateur, j’obtiens 5 disques par noeuds pour 5TB utiles. Auxquels j’ajoute un SSD de 250GB NVMe en MLC largement suffisant (5 x 1,2TB x 0,02)
Dans les 2 cas (SSD ou mécanique), il ne faut pas oublier les disques pour installer Proxmox et Ceph. Deux SSD de 250GB en RAID-1 font parfaitement l’affaire (exemple: Samsung 980 M.2 250GB).
Les processeurs
En plus de la charge de travail propre aux VMs, il faut considérer celle induite par le fonctionnement du stockage CEPH.
Voici les recommandations fournies par SUSE pour SES-7:
- 1x thread par disque rotatif
- 2x threads par disque SSD
- 4x threads par disque NVMe
Les 4 threads pour les disques NVMe paraissent un peu excessifs. Je vais retenir 12 threads par noeud dans notre cas d’étude (2 threads x 6 disques) auxquels il faut ajouter les ressources pour les services monitors et managers de CEPH (4 threads toujours selon SUSE).
Dans notre exemple, chaque noeud doit pouvoir supporter la charge de 50 VMs (100 VMs / 2 en cas de panne d’un noeud). J’utilise une méthode de calcul un peu empirique qui consiste à compter au moins un thread par VM. Bien sûr ça n’engage que moi mais la surallocation CPU est plutôt efficace et ce sont des valeurs confortables que je constate régulièrement sur d’autres clusters.
Si j’applique cette méthode, j’obtiens : 50 threads VMs + 16 threads CEPH = 66 threads. Dans la gamme Intel, il faudrait donc partir sur une configuration minimale avec deux processeurs Xeon Silver 4316 (2 x 20 coeurs HT @ 2,3Ghz).
La mémoire
La surallocation mémoire (memory overcommitment) est toujours moins efficace que pour les CPUs. J’ai tendance à ne pas jouer la contention dans ce domaine.
La mémoire consommée par CEPH est couramment évaluée (documentation REDHAT RHCS 4 et SUSE SES 7) à au moins 4GB par OSD. Là encore, il faut aussi prendre en compte les monitors et les managers (+32GB dans la doc Ceph)
Toujours dans notre cas d’étude, j’obtiens pour chaque noeud : (50 VMs * 2GB RAM) + (5 OSD x 4GB + 32GB) = 152 GB de RAM. La configuration la plus proche serait donc 12 barrettes de 16GB (192 GB de RAM) soit 6 barrettes par socket CPU.
Bien que fonctionnelle et économique, cette configuration ne permet pas d’exploiter toute la bande passante des processeurs modernes qui possèdent souvent 8 canaux mémoires.
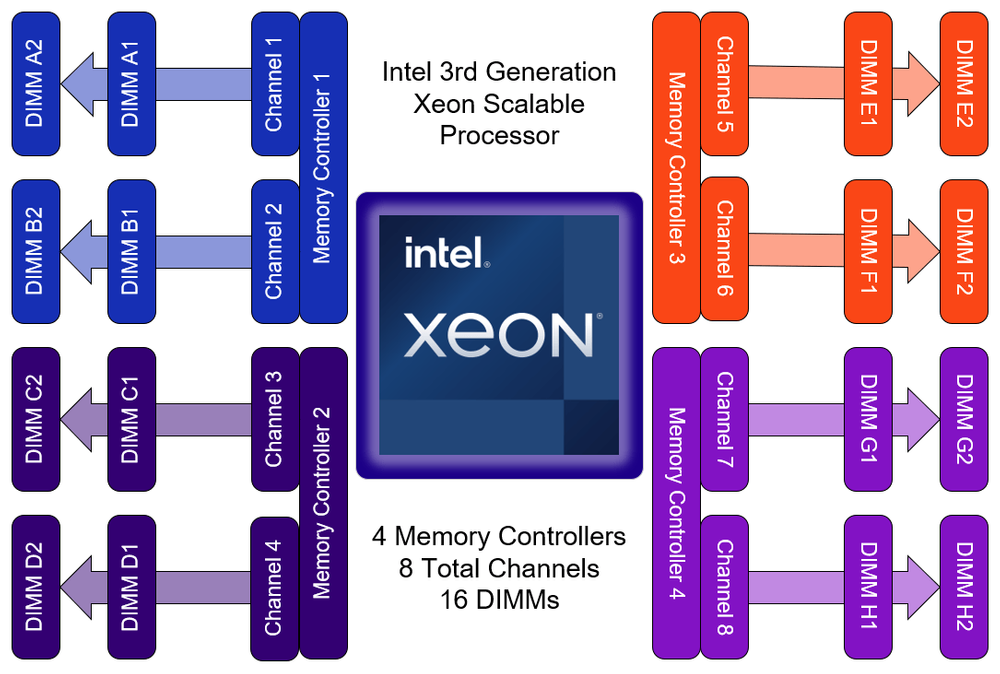
Voici un petit récapitulatif sur les processeurs récents:
- Intel Xeon de 1er et 2nd génération (Skylake et Cascade Lake): 6 canaux
- Intel Xeon de 3ème génération (Ice Lake): 8 canaux
- AMD EPYC de 1er à 4ème génération: 8 canaux
Si votre budget le permet, il est recommandé d’utiliser une configuration mémoire équilibrée (balanced memory configuration)
Ce graphique extrait de la documentation Dell met en évidence le gain de bande passante en fonction des banques mémoires occupées.
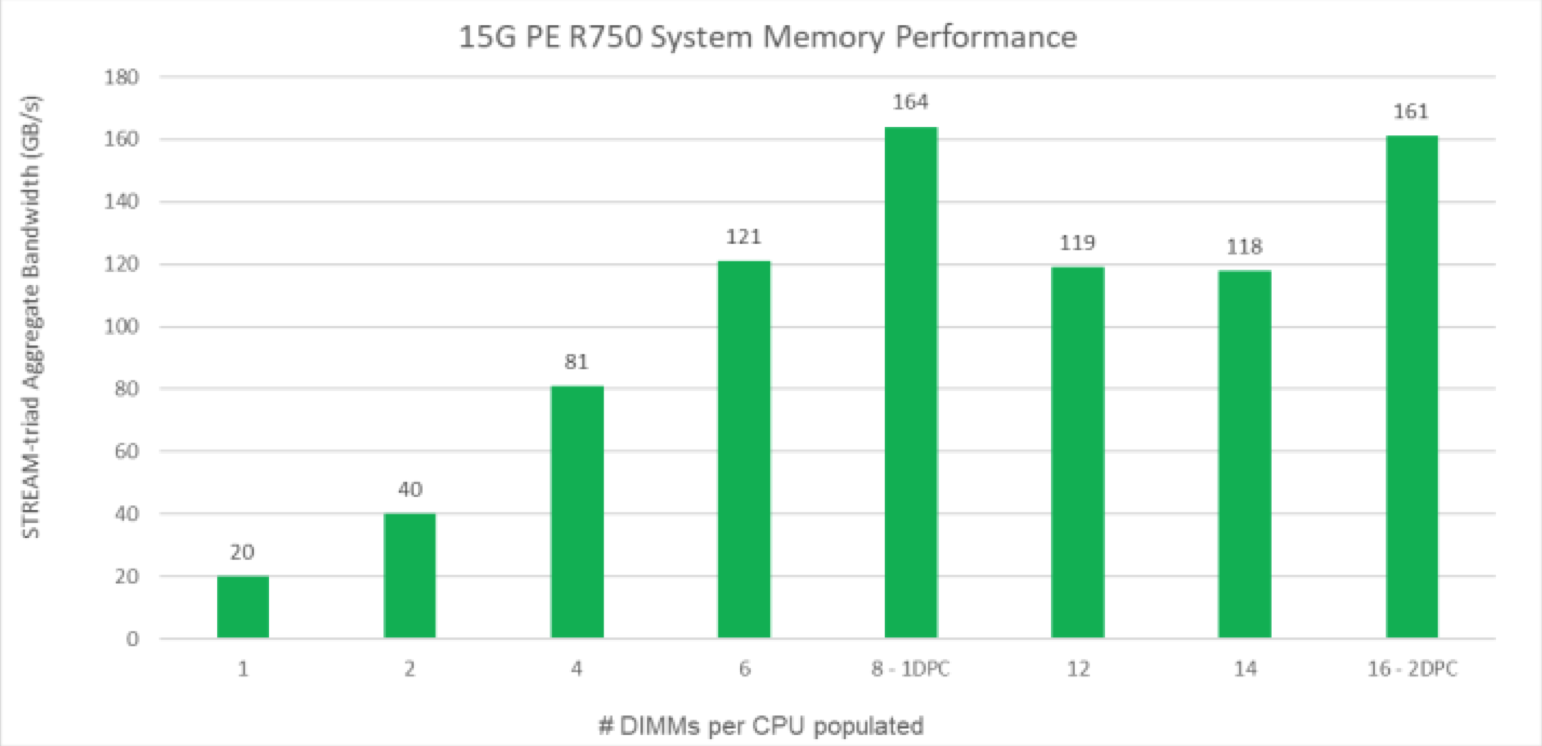
Le réseau
Comme je l’ai déjà évoqué un peu plus haut, Ceph sollicite beaucoup le réseau pour son fonctionnement normal et davantage encore dans les phases de reconstructions. En production, il ne faut pas hésiter à multiplier les interfaces pour bien segmenter les usages.
Ainsi, on peut distinguer 4 types de réseaux:
- les machines virtuelles
- le stockage Ceph
- l’administration (l’interface Web de Proxmox)
- le réseau cluster (pour Corosync)
Je vous propose le découpage suivant en partant du principe que les serveurs seront dans une armoire avec 2 commutateurs top-of-rack:
Les machines virtuelles
Un agrégat LACP de 2 interfaces 1GbE (minimum) avec les VLANs nécessaires aux VMs dans un trunk.
Le stockage Ceph
Un agrégat LACP de 2 interfaces 10GbE (minimum) dans un VLAN et un sous-réseau non routé dédié. N’hésitez pas à activer les jumbo-frames qui apportent un gain de performance significatif. Si vous ne pouvez pas disposer d’une connectivité 10GbE, Proxmox propose une topologie full mesh qui permet de relier directement les noeuds avec des DAC 10GbE sans équipements actifs.
L’administration et le reseau cluster
Ces 2 réseaux produisent peu de trafic et il peut être intéressant de les mutualiser dans un agrégat de 2 interfaces 1GbE en LACP pour avoir de la redondance. Pour autant, il reste important d’isoler les 2 flux dans des VLANs respectifs. Le réseau cluster est un élément-clé du fonctionnement de Proxmox et il mérite un sous-réseau dédié non routé pour correctement l’isoler. Attention, il ne doit jamais être mutualisé avec les interfaces de stockage Ceph. Si vous devez faire des concessions, il vaut mieux choisir les interfaces dédiées aux machines virtuelles.
Divers
Ceph est particulièrement sensible à la dérive temporelle et nécessite obligatoirement une synchronisation NTP de tous les noeuds. Enfin, comme toute infrastructure sensible, il est important de bien superviser le cluster. Si vous n’avez pas encore d’outil pour ça, je vous recommande Zabbix qui possède des extensions pour Proxmox et Ceph.
Conclusion
Ce billet est une synthèse des nombreuses documentations et autres blogs sur ce sujet. Si vous repérez des incohérences ou des approximations, n’hésitez pas à me les signaler pour que je puisse l’améliorer. Il ne reste plus qu’à mettre en pratique tout cela dans une preuve de concept qui fera l’objet du prochain article.