ZFS partie 1

Photo by Alexander Sinn on Unsplash
Si vous passez de temps en temps sur ce site, vous avez probablement remarqué un certain penchant pour le stockage. Aujourd’hui on va parler du petit surdoué: ZFS !
Cet article me trotte dans la tête depuis un moment mais j’attendais l’occasion idéale et justement j’ai une grosse bête de 256TB brut qui vient d’arriver sur mon bureau…

Dans cette première partie (la mise en oeuvre arrive bientôt..), on va s’attarder sur la terminologie propre à ZFS.
Je ne vais pas refaire la genèse complète de ZFS mais simplement retenir que ce système de fichiers a été développé à l’origine par Sun Microsystems avant de tomber dans l’escarcelle d’Oracle après le rachat de 2009.
Pour d’obscures raisons de licence, il n’a jamais été intégré au noyau GNU-Linux mais bénéficie d’un support mature grâce au projet ZFS On Linux.
Pourquoi ZFS ?
ZFS est bien plus qu’un système de fichiers, c’est à la fois un gestionnaire de volume (comme LVM) et un gestionnaire de RAID logiciel (comme mdadm).
Il possède des capacités de stockage quasi-illimitées (128 bits - 16 exbioctets) et une liste de fonctionnalités à faire pâlir la concurrence:
- snapshots
- compression à la volée
- déduplication à la volée
- réplication asynchrone (transfert incrémental de snapshot en ssh)
- mécanismes de cache (en ram ou sur disque)
- mécanismes d’auto-correction en ligne (crc / scrubbing)
Il est surtout extrêmement robuste grâce à un fonctionnement transactionnel en copy-on-write (CoW: les blocs à modifier ne sont pas directement écrasés mais copiés à un autre emplacement, les métadonnées sont ensuite modifiées pour pointer vers ce nouvel emplacement).
Comment ça marche ?
La gestion des disques:
ZFS est conçu pour utiliser directement les disques en mode JBOD. L’espace de stockage appelé ZPOOL est constitué d’un ou plusieurs VDEV (Virtual Device) pouvant contenir à leur tour un ou plusieurs disques physiques (ou partitions). Les VDEVs supportent différents types d’agrégations des disques pour obtenir de la performance ou inversement de la tolérance à la panne:
| type | nb mini (disque) | tolérance de panne (disque) | équivalence RAID | perte d’espace |
|---|---|---|---|---|
| stripe | 1 | aucune | RAID-O | aucune |
| mirror | 2 | (N-1) disque | RAID-1 | (N-1)/N disque |
| RAIDz-1 | 3 | 1 | RAID-5 | 1 disque |
| RAIDz-2 | 4 | 2 | RAID-6 | 2 disques |
| RAIDz-3 | 5 | 3 | triple parité | 3 disques |
Voici 3 exemples de configurations possibles (parmis d’autres) avec 12 disques physiques (disques de parité en rouge):
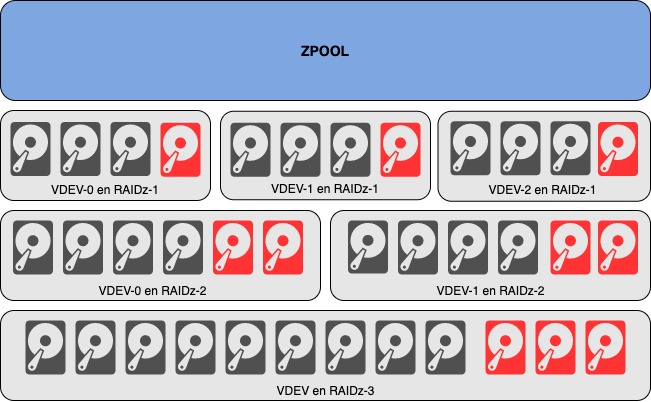
- 3 VDEVs en RAIDz-1 offre la meilleure performance mais avec fiabilité la plus faible. En cas de panne simultanée sur 2 disques d’un même VDEV, c’est tout le zpool qui est perdu !
- 2 VDEVs en RAIDz-2 offre le meilleur ratio performance / sécurité mais avec la volumétrie utile la plus faible.
- 1 VDEV en RAIDz-3 est intéressante pour favoriser la volumétrie typiquement pour un serveur de sauvegarde par exemple sans sacrifier la fiabilité.
Je n’ai pas détaillé la version composée de 6 VDEVs de 2 disques en mirroir. Elle permet d’offrir un maximum de performances pour héberger par exemple des machines virtuelles ou des bases de données.
On trouve encore beaucoup de ressources sur internet à propos de l’optimisation du nombre de disques dans un RAIDz-x. Il faut savoir que le recours systématique à la compression qui augmente à la fois les débits disques et la volumétrie rend ces considérations un peu obsolètes.
Dataset:
L’espace de stockage du zpool est consommé par des DATASET qui peuvent être soit:
- des systèmes de fichiers (plusieurs points de montage par exemple)
- des snapshots
- des clones
- des volumes ZVOL (des blocks pour faire de l’iSCSI ou pour formater avec un autre système de fichiers)
La commande zfs list -o space -r <zpool_name> permet de visualiser les datasets avec la consommation d’espace des snapshots. La commande simple zfs list permet de voir les points de montages des datasets. En l’absence de quota défini, les datasets peuvent consommer l’intégralité de l’espace de stockage du pool (zfs set quota=10G <zpool_name>/<dataset_name>).
1$ zfs list -o space -r tank
2NAME AVAIL USED USEDSNAP USEDDS USEDREFRESERV USEDCHILD
3tank 53.7T 2.45T 0B 192K 0B 2.45T
4tank/mariadb 53.7T 3.26G 2.89G 375M 0B 0B
5tank/home 53.7T 2.42T 472G 1.95T 0B 0B
6tank/opt 53.7T 20.6G 189M 20.5G 0B 0B
7
8$ zfs list
9NAME USED AVAIL REFER MOUNTPOINT
10tank 2.45T 53.7T 192K none
11tank/mariadb 3.25G 53.7T 375M /var/lib/mysql
12tank/home 2.42T 53.7T 1.95T /home
13tank/opt 20.6G 53.7T 20.5G /opt
Adaptive Replacement Cache:
L’ARC (Adaptive Replacement Cache) est un mécanisme de cache utilisant la RAM de la machine. Il stocke à la fois des données et des métadonnées du système de fichiers. Il permet d’améliorer les performances en limitant les accès disques. Par défaut, il peut consommer jusqu’à 50% de la RAM disponible sur le serveur.
Quelques commandes pour contrôler le fonctionnement de l’ARC (ici un peu tronquées…)
1$ cat /proc/spl/kstat/zfs/arcstats |grep c_ //serveur de 64GB de RAM
2c_min 4 2095271808
3c_max 4 33524348928
4
5
6$ arc_summary
7------------------------------------------------------------------------
8ZFS Subsystem Report Fri Nov 19 13:07:57 2021
9Linux 5.4.0-89-generic 0.8.3-1ubuntu12.12
10Machine: server_name 0.8.3-1ubuntu12.12
11
12ARC status: HEALTHY
13 Memory throttle count: 0
14
15
16$ arcstat
17 time read miss miss% dmis dm% pmis pm% mmis mm% arcsz c
1813:20:38 0 0 0 0 0 0 0 0 0 31G 31G
Layer 2 ARC:
Le L2ARC (Layer 2 ARC) est un cache facultatif sur disque rapide (SSD) alimenté en continu par les données qui vont être prochainement éjectées du cache ARC. Attention, le L2ARC a besoin de RAM pour fonctionner et peut entrainer une perte de performance si la mémoire pour l’ARC n’est pas suffisante. En règle générale on considère qu’un L2ARC ne devrait pas être ajouté à un système avec moins de 64 Go de RAM, et la taille d’un L2ARC ne devrait pas dépasser cinq fois la quantité de RAM. La défaillance d’un disque L2ARC n’est pas critique pour ZFS. On peut se contenter de mettre un seul disque ou à la rigueur plusieurs SSD en striping pour augmenter les performances.
1## analyse des performances du cache L2ARC
2$ cat /proc/spl/kstat/zfs/arcstats | egrep 'l2_(hits|misses)'
3l2_hits 4 6535623
4l2_misses 4 1098440663
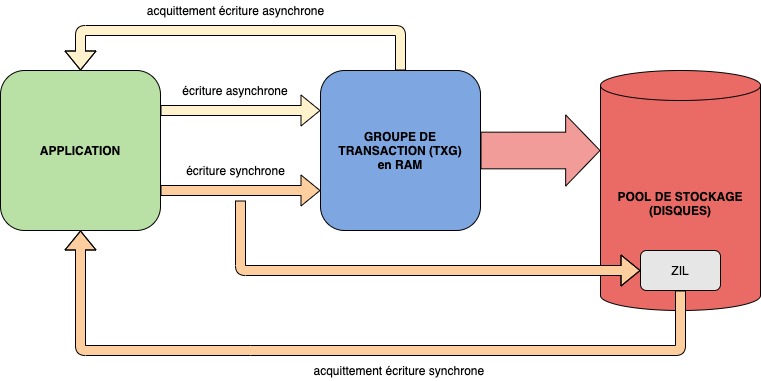
ZIL / SLOG / TXG:
Mon objectif est de mettre en place un gros NAS avec un partage NFS pour des serveurs de calculs. NFS fonctionne avec des écritures synchrones et va donc solliciter le journal d’intention de ZFS (ZIL: ZFS Intent Log). Son rôle est de garantir la consistance des écritures en cas de panne. Il est souvent assimilé à tort à un cache en écriture.
Par défaut, le ZIL est localisé sur les mêmes disques que les données. L’écriture des données synchrones entraine donc une double pénalité (dans le ZIL ET dans le pool de données). Avec des disques mécaniques, les performances en écriture peuvent être fortement pénalisées.
La solution consiste à déporter le ZIL sur des périphériques adaptés (SSD ou PMEM), on parle alors de SLOG (Separate ZFS Intent Log)
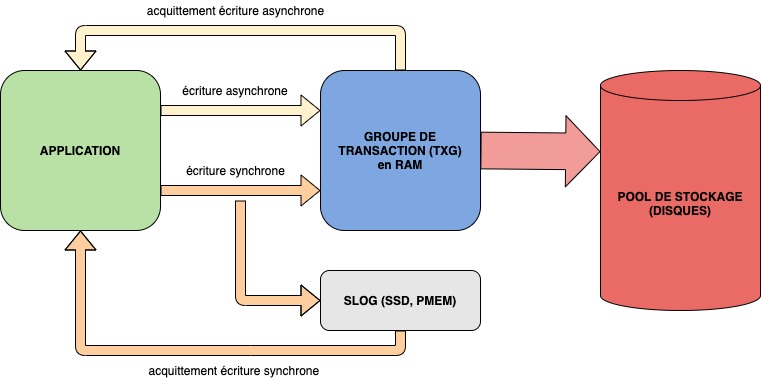
En cas de panne électrique par exemple, l’intégrité du volume de stockage ZFS est garantie par le rejeu des données présentes dans le SLOG.
Les groupes de transaction (TXG: Transaction Groups) sont une autre particularité de ZFS. Ils permettent d’organiser les données en mémoire avant de les déverser toutes les 5 secondes (par défaut) dans le pool de stockage pour optimiser les accès disques. ZFS garantit la consistance des données pour chaque groupe de transaction avec un identifiant sur 64 bits .
La taille du SLOG est directement liée aux groupes de transaction. Dans ZFS on Linux, les groupes de transactions font 10% de la RAM dans une limite de 4GB. Comme ZFS peut avoir jusqu’à 3 TXG actifs en simultanés, on peut estimer la taille du SLOG à 12GB maximum. Avec 2 SSD (il est recommandé d’utiliser un mirroir) de 32GB en MLC (endurance) on couvre largement le besoin pour un coût dérisoire.
La commande zpool status permet de visualiser la configuration complète d’un pool ZFS.
- une section
tank: avec les disques de stockages en RAIDz2 - une section
Logs: pour le SLOG avec les 2 SSD en mirroir - une section
cache: pour le SSD L2ARC.
1 NAME STATE READ WRITE CKSUM
2 tank ONLINE 0 0 0
3 raidz2-0 ONLINE 0 0 0
4 disk00 ONLINE 0 0 0
5 disk01 ONLINE 0 0 0
6 disk02 ONLINE 0 0 0
7 disk03 ONLINE 0 0 0
8 disk04 ONLINE 0 0 0
9 disk05 ONLINE 0 0 0
10 raidz2-1 ONLINE 0 0 0
11 disk06 ONLINE 0 0 0
12 disk07 ONLINE 0 0 0
13 disk14 ONLINE 0 0 0
14 disk15 ONLINE 0 0 0
15 disk16 ONLINE 0 0 0
16 disk17 ONLINE 0 0 0
17 logs
18 mirror-2 ONLINE 0 0 0
19 ssd09-part1 ONLINE 0 0 0
20 ssd10-part1 ONLINE 0 0 0
21 cache
22 ssd11-part1 ONLINE 0 0 0
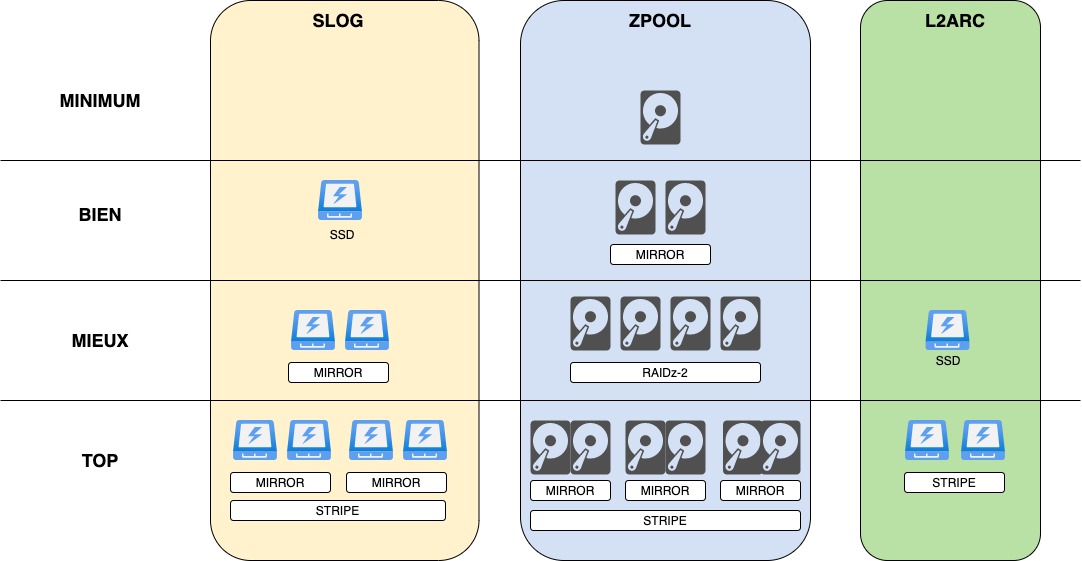
Le schéma ci-dessous les recommandations d’organisations des disques dans ZFS:
Conclusion
Maintenant que la terminologie ZFS n’a plus de secret pour vous, je vous propose d’aborder concrétement la configuration du serveur dans le prochain article…